Zusammenhang zwischen metrischen Variablen
Darstellung von Zusammenhängen
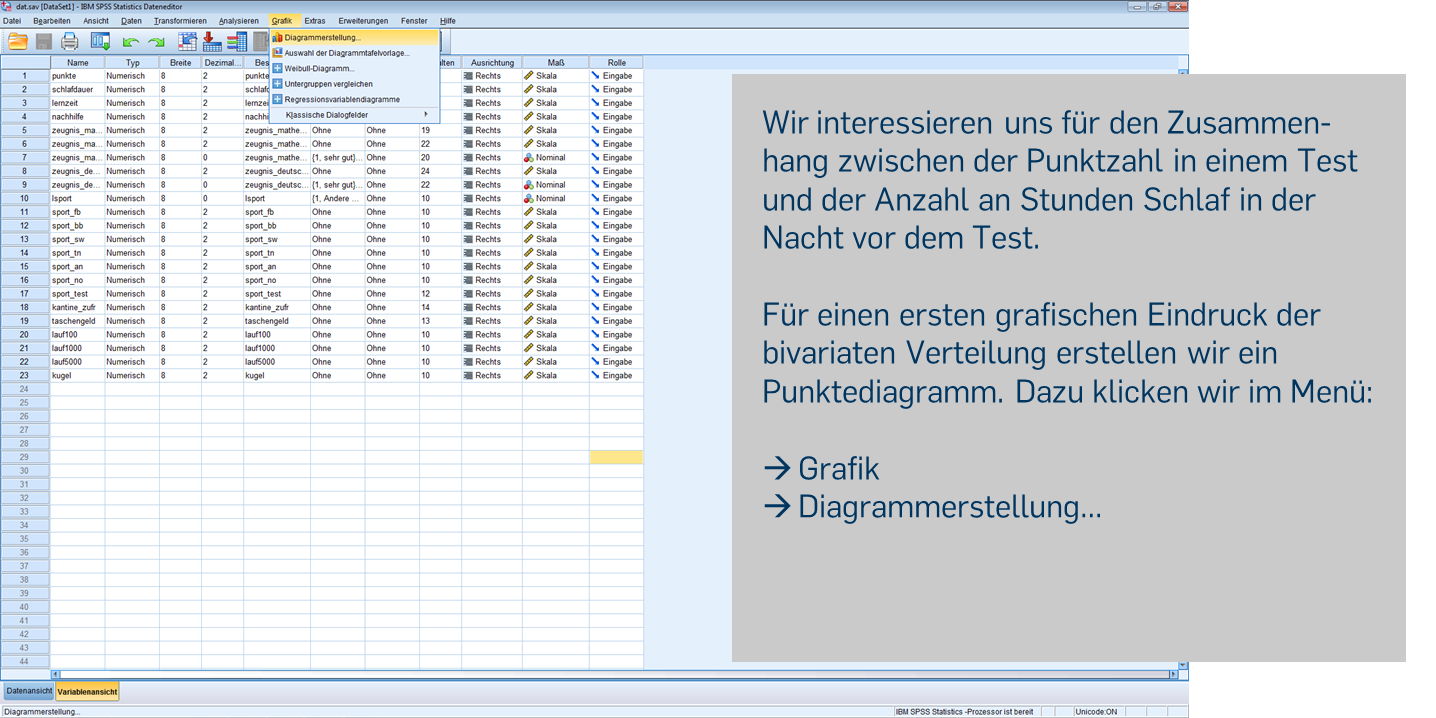
Zur Erinnerung: Je nach Skalenniveau der beiden Variablen lassen sich zwei Merkmale in unterschiedlicher Weise gemeinsam darstellen. Zwei metrische Variablen lassen sich in einem Punktdiagramm abbilden.









Hier finden Sie Informationen zu den im Artikel verwendeten Beispieldaten.
Korrelation
Der Korrelationskoeffizient \(r\) nach Bravais und Pearson — auch Produkt-Moment-Korrelation genannt — ist ein Maß für den linearen Zusammenhang zweier kontinuierlicher/metrischer Variablen.
Eigenschaften
- \(r\) kann Werte zwischen \(-1\) und \(1\) annehmen.
- Ein Wert von \(0\) bedeutet, dass kein Zusammenhang vorliegt.
- Negative Werte repräsentieren einen negativen Zusammenhang, positive Werte weisen dementsprechend auf einen positiven Zusammenhang hin.
- Je weiter der Wert von \(0\) entfernt ist, desto stärker ist der Zusammenhang.
- Der untersuchte Zusammenhang wird als ungerichtet angenommen, d.h. es wird keine Wirkrichtung zwischen den Variablen festgelegt. Wir sprechen also nicht von abhängigen und unabhängigen Variablen.
Grundidee
Wir berechnen mit \(r\), ob und wie sehr über-(unter)durchschnittliche Werte auf einer Variablen mit über- oder unterdurchschnittlichen Werten auf der anderen Variablen einhergehen. Die Stärke dieses Zusammenhangs können wir mit \(r\) in einer konkreten Zahl ausdrücken.
Der Grund liegt in dem oben gezeigten Konstruktionsprinzip, den bivariaten Merkmalsraum (d.h. bildlich, die Fläche des Streudiagramms) anhand der Mittelwerte in vier Quadranten zu teilen — denn schon dieser Mittelwert allein kann für nicht-metrische Variablen nicht berechnet werden!
Interpretation
Zur Interpretation der Stärke des Zusammenhangs gibt es verschiedene Faustregeln, z.B. nach Kühnel & Krebs (2007, S. 404f.):
| Stärke des Zusammenhangs | Wertebereich von r |
|---|---|
| Kein Zusammenhang | \(0 |
| Geringer Zusammenhang | \(0,05 |
| Mittlerer Zusammenhang | \(0,2 |
| Hoher Zusammenhang | \(0,5 |
| Sehr hoher Zusammenhang | \(|r| > 0,7\) |
Als Zusammenhangsmaß für metrische Variablen kann uns auch der Begriff der Kovarianz begegnen. Die Kovarianz wird zur Berechnung von \(r\) verwendet und ist unstandardisiert. Das bedeutet, dass die Größe der Kovarianz nicht nur von dem linearen Zusammenhang sondern auch von den Einheiten der Variablen abhängig ist. Im Vergleich zur Kovarianz können wir mit dem Korrelationskoeffizienten \(r\) also die Stärke eines Zusammenhangs besser beurteilen und verschiedene Zusammenhangshypothesen besser vergleichen.
Herleitung des Korrelationskoeffizienten nach Bravais und Pearson
Zusammenfassung
Praktische Umsetzung mit Statistiksoftware
Beispieldaten herunterladen: dat.csv
Datenbeispiel
Unser Beispieldatensatz (hypothetisches Datenbeispiel) liegt als CSV-Datei vor. Die Daten können mit der read.csv-Funktion eingelesen werden (der korrekte Pfad zum Speicherort muss angegeben werden):
dat <- read.csv("C:/... Pfad .../dat.csv")Die Funktion erzeugt ein Objekt vom Typ data.frame, dem wir links vom Zuweisungspfeil (<-) den Namen "dat" geben.
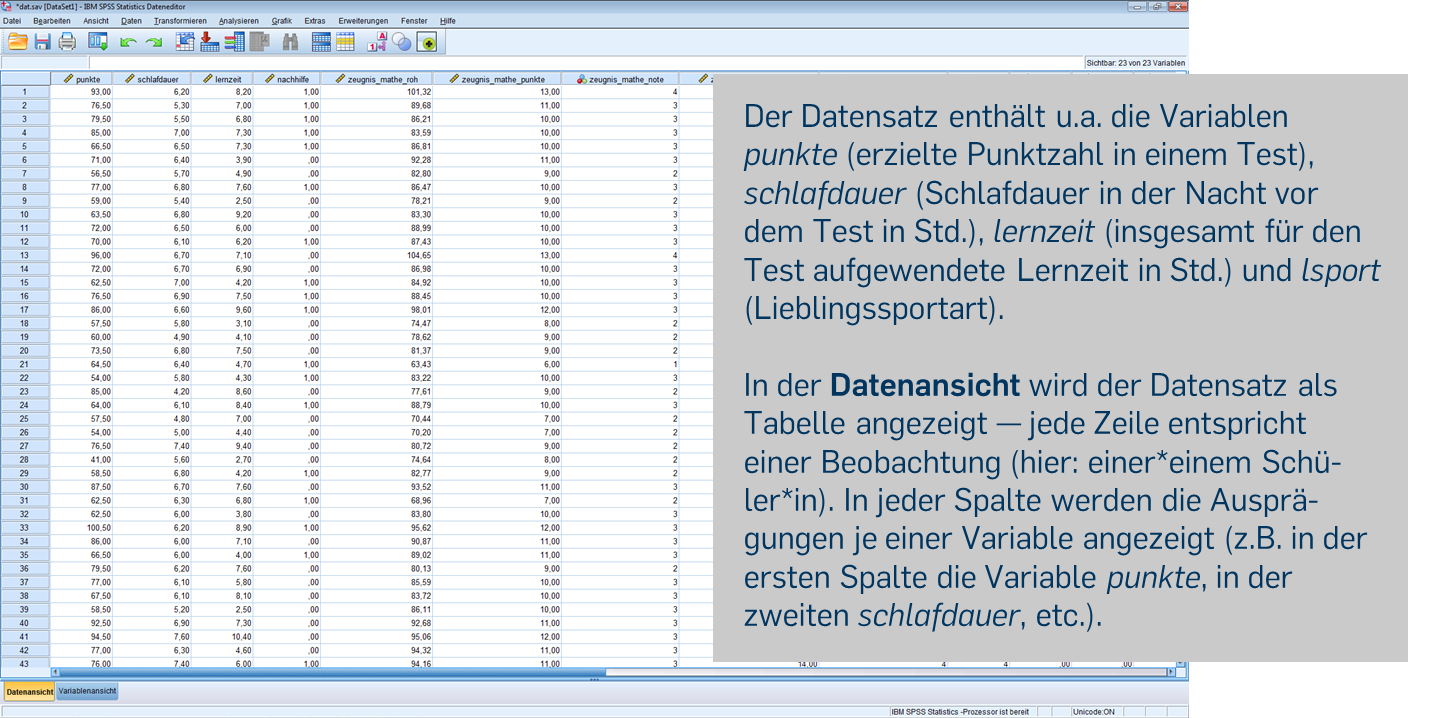
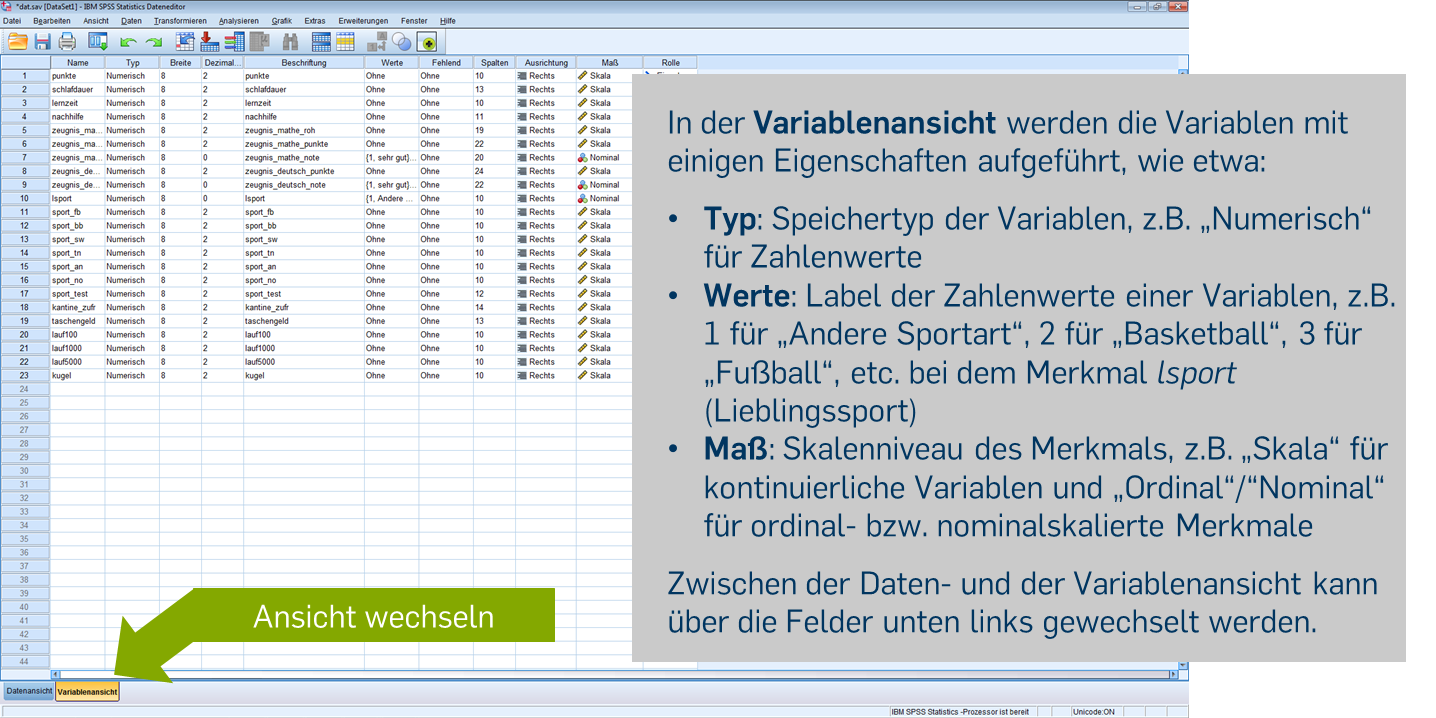
Der Datensatz enthält u.a. die Variablen punkte (erzielte Punktzahl in einem Test), schlafdauer (Schlafdauer in der Nacht vor dem Test in Std.), lernzeit (insgesamt für den Test aufgewendete Lernzeit in Std.) und lsport (Lieblingssportart). Einzelne Variablen können als Datensatzname$Variablenname angesprochen werden, z.B.:
dat$punkte
>[1] 93.0 76.5 79.5 85.0 66.5 71.0 56.5 77.0 59.0 63.5 72.0 70.0 96.0 72.0 62.5 76.5 86.0 57.5
[19] 60.0 73.5 64.5 54.0 85.0 64.0 57.5 54.0 76.5 41.0 58.5 87.5 62.5 62.5 100.5 86.0 66.5 79.5
[37] 77.0 67.5 58.5 92.5 94.5 77.0 76.0 67.0 44.5 86.5 70.0 81.5 90.5 78.0 80.5 74.0 56.5 60.0
[55] 83.0 70.0 49.0 57.0 48.0 70.5 96.5 106.0 65.5 86.5 87.5 89.5 64.0 86.0 62.0 94.5 52.0 73.5
[73] 77.0 83.5 62.5 52.5 51.5 86.5 70.5 57.5 68.0 103.0 79.0 75.0 113.5 78.0 104.5 84.5 63.5 46.0
[91] 102.5 77.0 73.5 71.0 106.0 79.0 77.5 87.0 92.5 11.5 83.5 86.5 78.5 67.5 71.0 61.5 31.0 50.5
[109] 87.5 66.5 67.0 60.5 61.5 83.5 66.0 97.0 79.5 83.5 82.0 63.0Die Ausgabe zeigt die 120 beobachteten Werte der Variable punkte.
Punktediagramm
Ein Punktediagramm für die Variablen Schlafdauer und Punktzahl kann mit dem plot()-Befehl erzeugt werden:
plot(x=dat$schlafdauer,
y=dat$punkte,
xlab="Schlafdauer vor der letzten Matheklausur",
ylab="Punktzahl in der letzten Matheklausur",
main="Zusammenhang Punktezahl Matheklausur–Schlafdauer")
Um eine besser Übersicht zu erhalten, kann auch der Mittelwert der Schlafdauer und der Punktezahl mit abline() in das Streudiagramm eingezeichnet werden:
abline(h=mean(dat$punkte), lty="dashed")
abline(v=mean(dat$schlafdauer), lty="dashed")Korrelationskoeffizient nach Pearson:
Der Korrelationskoeffizient nach Pearson kann (u.a.) mit der Funktion cor() berechnet werden:
> cor(x= dat$punkte, y=dat$schlafdauer, method="pearson")
[1] 0.4315438 Der Funktion kann auch ein data.frame mit mehreren metrischen Variablen übergeben werden, wir erhalten eine Matrix der Korrelationen aller Variablen untereinander:
> # Datensatz mit drei metrischen Variablen anlegen:
> datcorr <- data.frame(dat$punkte, dat$schlafdauer, dat$lernzeit)
> # Korrelationen berechnen:
> cor(datcorr)
dat.punkte dat.schlafdauer dat.lernzeit
dat.punkte 1.0000000 0.4315438 0.7275106
dat.schlafdauer 0.4315438 1.0000000 0.3318054
dat.lernzeit 0.7275106 0.3318054 1.0000000Hinweis: liegen auf einer oder beiden Variablen fehlende Werte (NAs) vor, sollte in der Regel als weiteres Argument use="pairwise.complete.obs" angegeben werden. Mit "pairwise.complete.obs" werden fehlende Werte nach dem pairwise deletion-Prinzip entfernt: Fehlt der Wert einer für eine Korrelationsberechnung benötigte Variable bei einer Beobachtung, wird diese nicht berücksichtigt. Im Fall einer Korrelationsmatrix kann man sich auch für use="complete.obs" entscheiden wollen - eine Beobachtung wird dann für alle Korrelationsberechnungen ausgeschlossen, sobald nur auf einer Variable ein fehlender Wert vorliegt.
> cor(x= dat$punkte, y=dat$schlafdauer, method="pearson", use="complete.obs")
[1] 0.4315438 (Da hier keine fehlenden Werte vorliegen, unterscheidet sich das Ergebnis nicht von der vorherigen Berechnung.)
Beispieldaten herunterladen: daten_stata.dta
Daten einlesen
Der Datensatz wird mit dem Befehl use eingelesen
use "C:\...Pfad...\dat.dta"Die Variablen können nun direkt mit ihrem Variablennamen ("punkte", "schlafdauer" usw.) angesprochen werden.
Punktdiagramm
Ein Punktediagramm für die Variablen Schlafdauer und Punktzahl kann mit
scatter punkte schlafdauer, ytitle("Punktzahl in der letzten Matheklausur") xtitle("Schlafdauer vor der letzten Matheklausur") title("Zusammenhang Punktezahl Matheklausur–Schlafdauer")
erzeugt werden.

Um eine noch bessere Übersicht zu erhalten, können auch die Mittelwerte der Schlafdauer und der Punktezahl mit den Optionen xline und yline als Linien in das Streudiagramm eingezeichnet werden. Dafür müssen die beiden Kennzahlen zuerst ermittelt werden. Dies geschieht mit dem summarize Befehl:
summarize punkte
> Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
punkte | 120 73.23333 16.29455 11.5 113.5
summarize speichert die Ergebnisse in r() zwischen—das arithmetische Mittel ist als r(mean) hinterlegt. Das Ziel ist es nun diese Kennzahl lokal zu speichern. Dafür verwenden wir den local Befehl und speichern den Mittelwert als mean_punkte (dem Objekt kann ein beliebiger gütiger Name gegeben werden):
local mean_punkte = r(mean)
Derselbe Prozess wird auch für schlafdauer durchgeführt:
summarize schlafdauer
> Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
schlafdauer | 120 6.185833 .7184596 4.2 7.8
local mean_schlafdauer = r(mean)
Um nun das Streudiagramm mit den beiden Linien zu erstellen, wird der bereits bekannte scatter Befehl mit yline() und xline() ergänzt. Die lokal gespeicherten Ergebnisse werden mit `Objektname' angesprochen:
scatter punkte schlafdauer, ytitle("Punktzahl in der letzten Matheklausur") xtitle("Schlafdauer vor der letzten Matheklausur") title("Zusammenhang Punktezahl Matheklausur–Schlafdauer") yline(`mean_punkte') xline(`mean_schlafdauer')

Korrelationskoeffizient
Der Korrelationskoeffizient nach Pearson wird in Stata mit der Funktion correlate ermittelt:
correlate punkte schlafdauer
(obs=120)
> | punkte schlaf~r
-------------+------------------
punkte | 1.0000
schlafdauer | 0.4315 1.0000
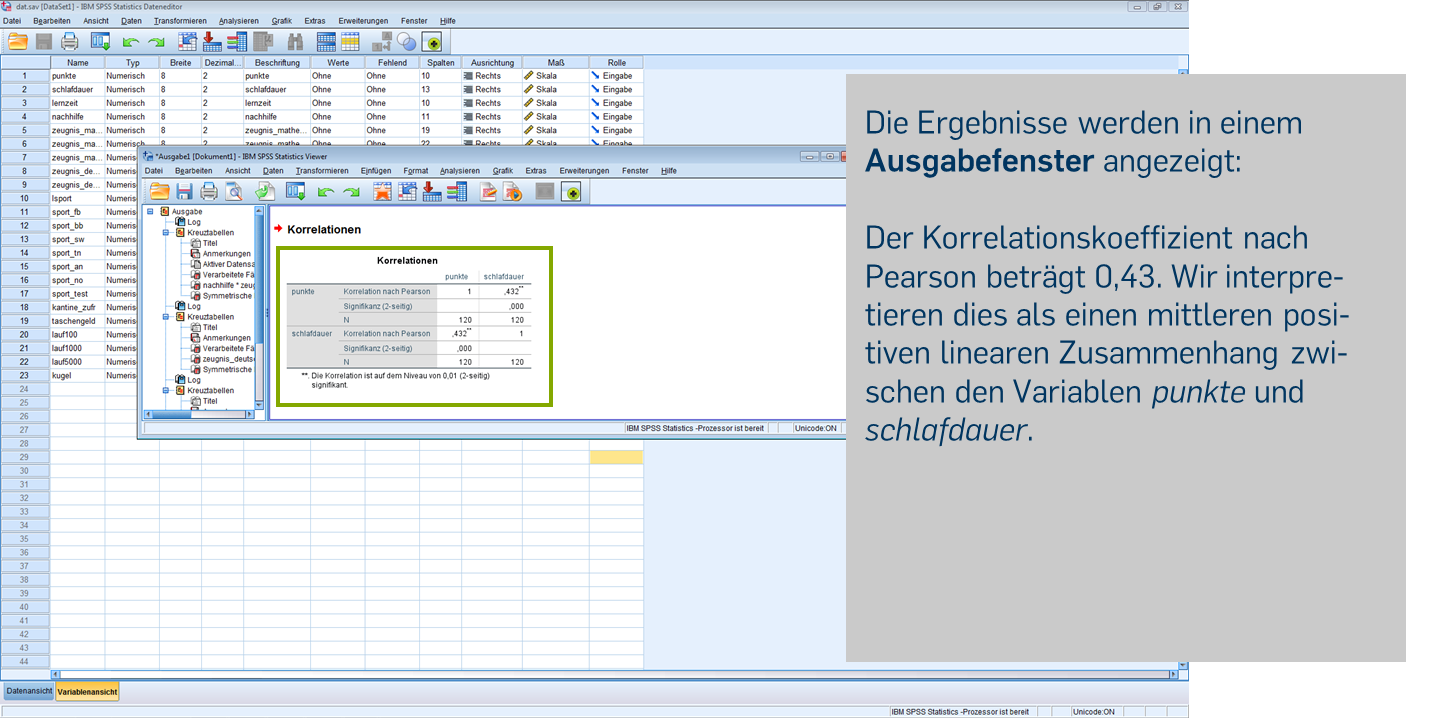
Der Korrelationskoeffizient nach Pearson beträgt 0,43. Wir interpretieren dies als einen mittleren positiven linearen Zusammenhang zwischen den Variablen punkte und schlafdauer. (Die Korrelationskoeffizienten der Variablen mit sich selbst sind 1, da sie perfekt mit sich selbst korrelieren.)
Der Funktion können mehr als zwei Variablen übergeben werden. Die Ausgabe erfolgt dann als Korrelationsmatrix.
correlate punkte schlafdauer lernzeit
(obs=120)
| punkte schlaf~r lernzeit
-------------+---------------------------
punkte | 1.0000
schlafdauer | 0.4315 1.0000
lernzeit | 0.7275 0.3318 1.0000
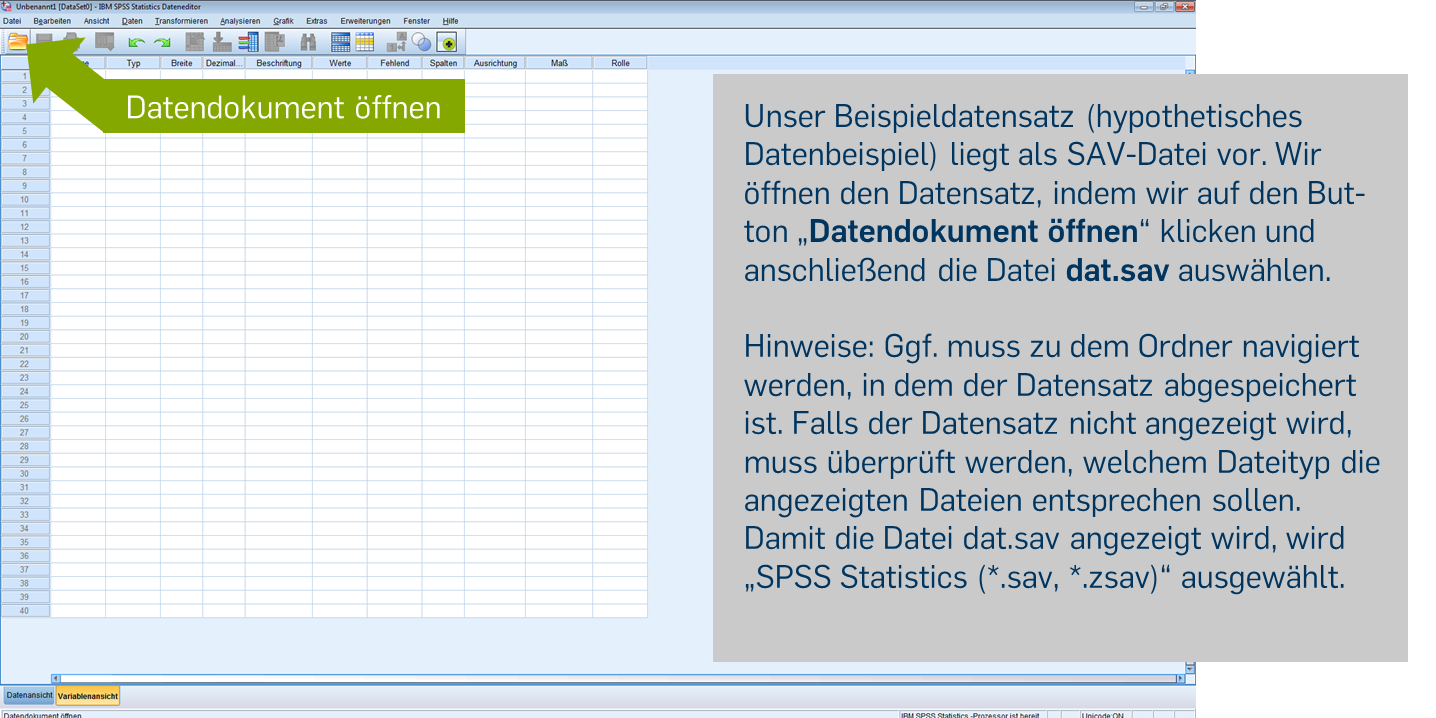
Beispieldaten herunterladen: dat.sav
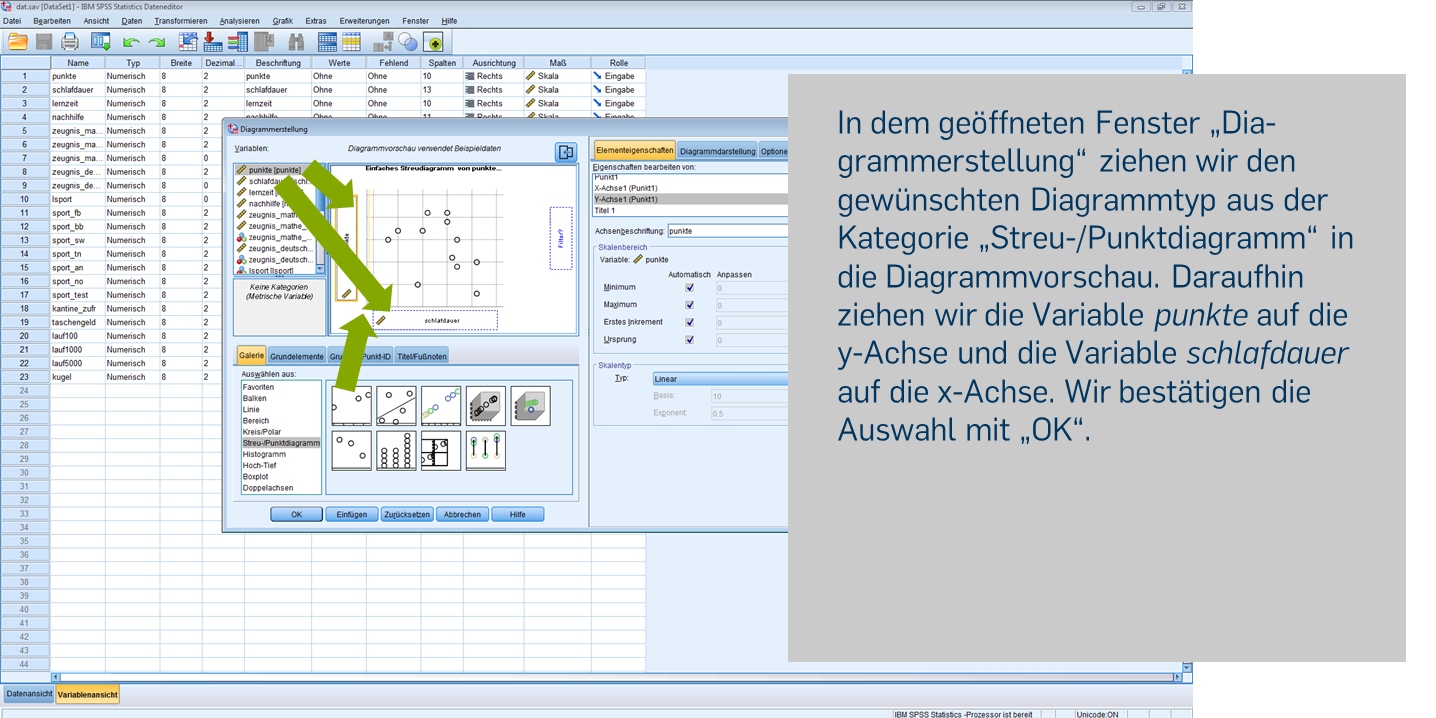
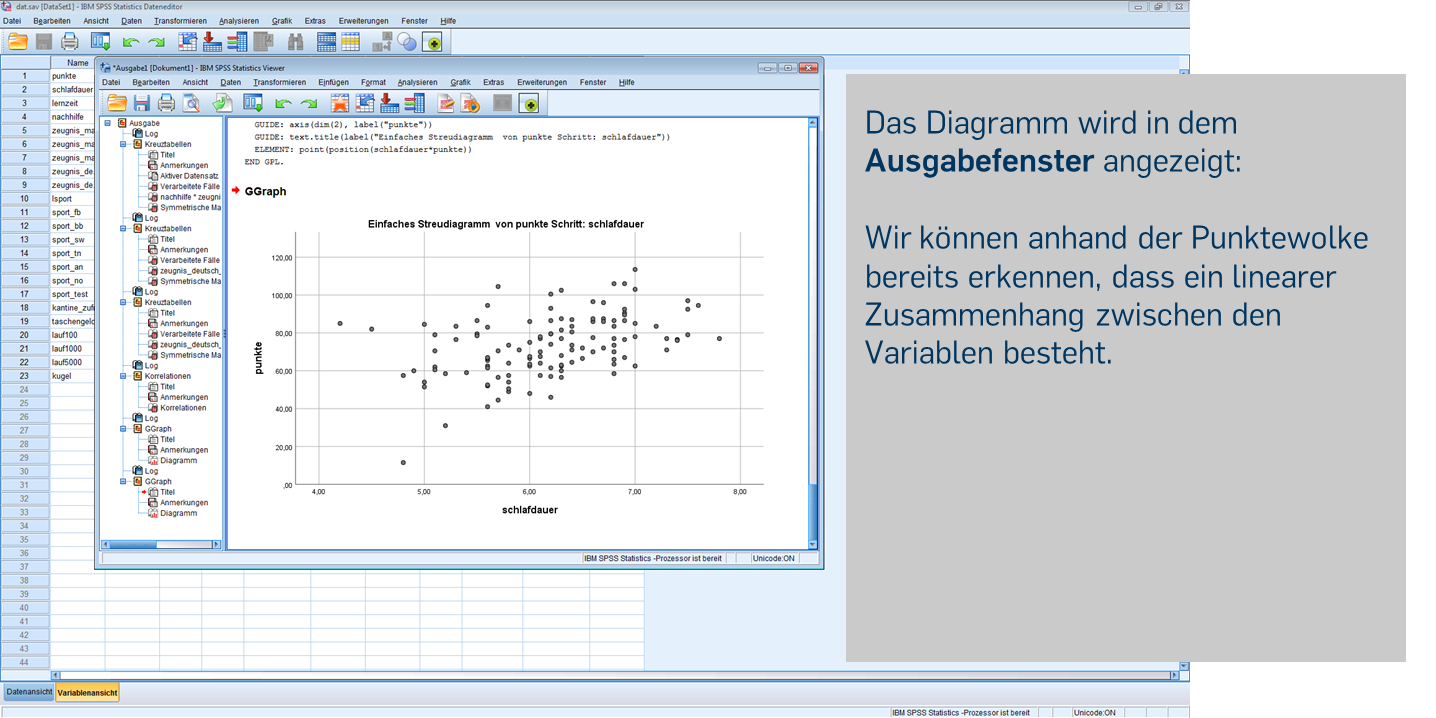
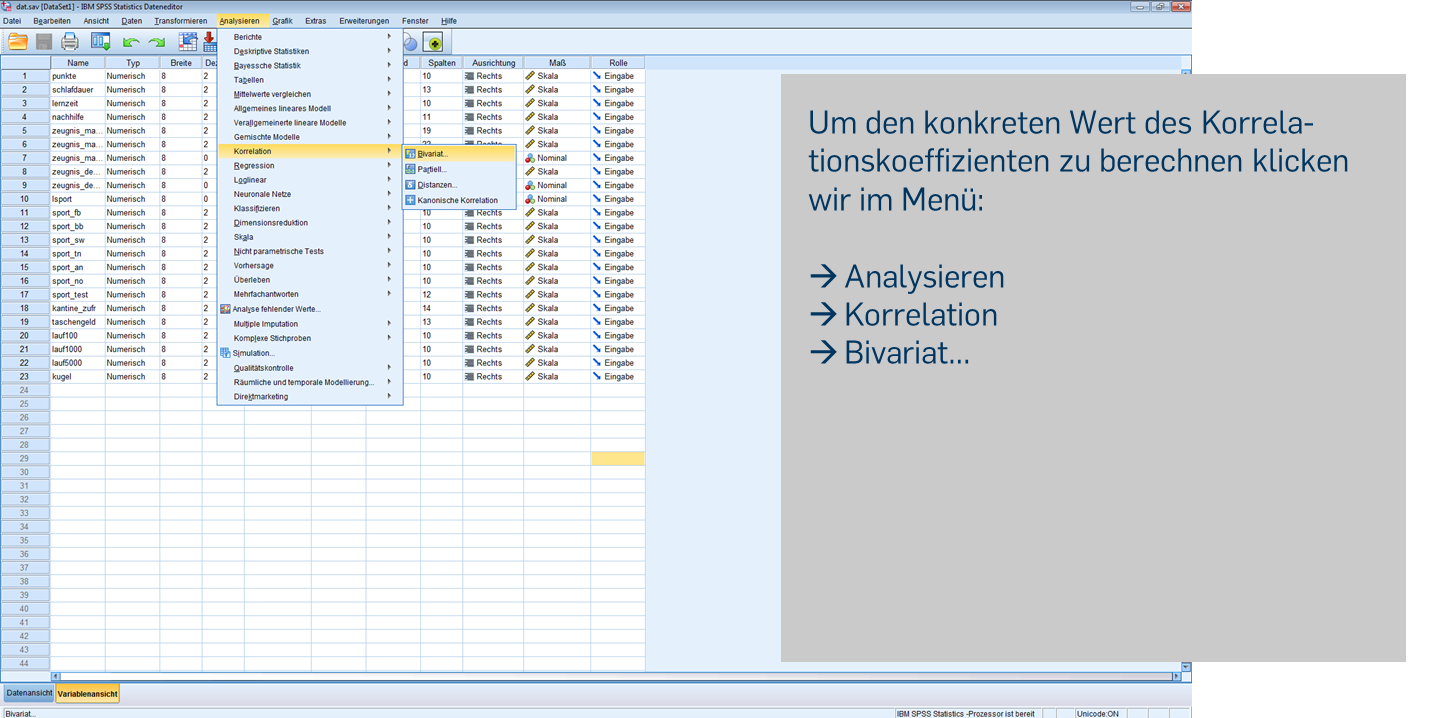
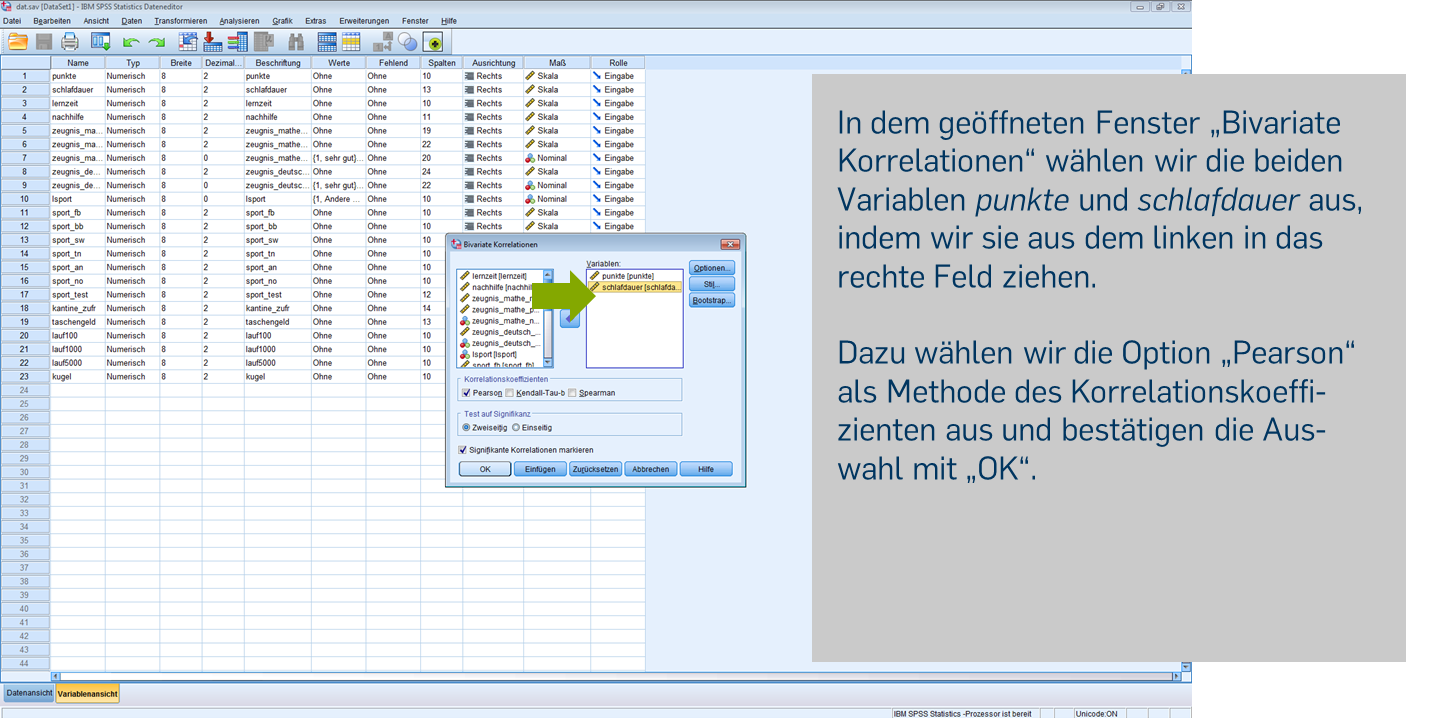
Statt durch Klicken durch das Menü können wir uns die Ergebnisse auch über die Syntax ausgeben lassen. Für das Diagramm verwenden wir den folgenden Code:
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=schlafdauer punkte MISSING=LISTWISE REPORTMISSING=NO
/GRAPHSPEC SOURCE=INLINE
/FITLINE TOTAL=NO.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: schlafdauer=col(source(s), name("schlafdauer"))
DATA: punkte=col(source(s), name("punkte"))
GUIDE: axis(dim(1), label("schlafdauer"))
GUIDE: axis(dim(2), label("punkte"))
GUIDE: text.title(label("Einfaches Streudiagramm von punkte Schritt: schlafdauer"))
ELEMENT: point(position(schlafdauer*punkte))
END GPL.Mit dem Befehl GGRAPH erzeugen wir die Abbildung und mit dem Befehl GPL modifizieren wir sie. Unter GRAPHDATASET vergeben wir einen Namen, auf den wir uns in dem GPL-Befehl beziehen. SOURCE=INLINE führt dazu, dass der momentan geöffnete Datensatz verwendet wird. Die x-Achse wird als dim(1) bezeichnet und die y-Achse als dim(2).
Für den Korrelationskoeffizienten verwenden wir den folgenden Code:
CORRELATIONS
/VARIABLES=punkte schlafdauer.Wir verwenden den Befehl "CORRELATION" und geben mit "VARIABLES=" die Variablen an, für deren Zusammenhang wir uns interessieren.