Univariate Verteilungen
Univariate Verteilungen







Hier finden Sie weitere Informationen zu den im Artikel verwendeten Beispieldaten.
Empirische Häufigkeitsverteilungen
Die empirische Häufigkeitsverteilung einer Variable beschreibt, welche Werte in der betrachteten Gesamtheit wie häufig auftreten. Wenn wir von der Verteilung der Variable Klausurnote in der Gesamtheit Klasse 9b sprechen, meinen wir: Wie viele Einsen, Zweien, Dreien, ... gab es jeweils? Oder genauer: Bei wie vielen Untersuchungseinheiten (Schüler*innen der 9b) haben wir ein "sehr gut" beobachtet, bei wie vielen ein "gut", und so weiter.
Eine Variable (oder: ein Merkmal) ist eine Eigenschaft der Untersuchungseinheiten (häufig: der befragten oder anders beforschten Personen), die unterschiedliche Ausprägungen oder Werte annehmen kann.
Folgende Fragen sind wichtig, wenn wir von einer Variable sprechen:
- Über wen sprechen wir? → Die Untersuchungseinheiten sind Schüler*innen.
- Wie nennen wir das Merkmal, über das wir sprechen? \( \rightarrow \) Das Merkmal/die Variable heißt Klausurnote.
- Welche unterschiedlichen Werte kann es da geben? \( \rightarrow \) Der Merkmalsraum umfasst die Ausprägungen ungenügend, mangelhaft, ausreichend, befriedigend, gut, sehr gut.
Zu beachten:
- Jede Untersuchungseinheit (Schüler*in) weist genau eine Ausprägung auf.
- (Nur) bei metrischen Variablen sprechen wir anstatt von Ausprägungen auch von Werten.
- Es kann vorkommen, dass mehr Ausprägungen möglich sind als in unserer Untersuchungsgesamtheit realisiert werden ("Curling" gehört zum Merkmalsraum der Variable "Lieblingssport", auch wenn es kein*e Schüler*in mit diesem Lieblingssport gibt). Die Menge aller Werte, die auftreten könnten nennen wir deshalb den theoretischen Merkmalsraum.








Univariate Verteilungen beschreiben
In der Regel wird uns bei einer empirischen Forschungsarbeit nicht jedes kleine Detail in den Rohdaten interessieren. Das Ziel ist vielmehr, die wesentlichen Aspekte der Verteilung beschreiben zu können. Was interessiert uns an einer Häufigkeitsverteilung?
Typische Werte: Gemeint sind entweder besonders häufige Werte oder "Mittelwerte" (Werte im Zentrum des beobachteten Wertebereichs).
Über die Verteilung der Klausurnoten möchten wir vermutlich als erstes Wissen, wie gut die Schüler*innen abgeschnitten haben. Gab es viele "Gut" und "Sehr gut", oder mehr "Ausreichend" und "Befriedigend"? Wir möchten also wissen, in welchem Wertebereich "die Verteilung liegt" und sprechen daher auch von Lagemaßen.
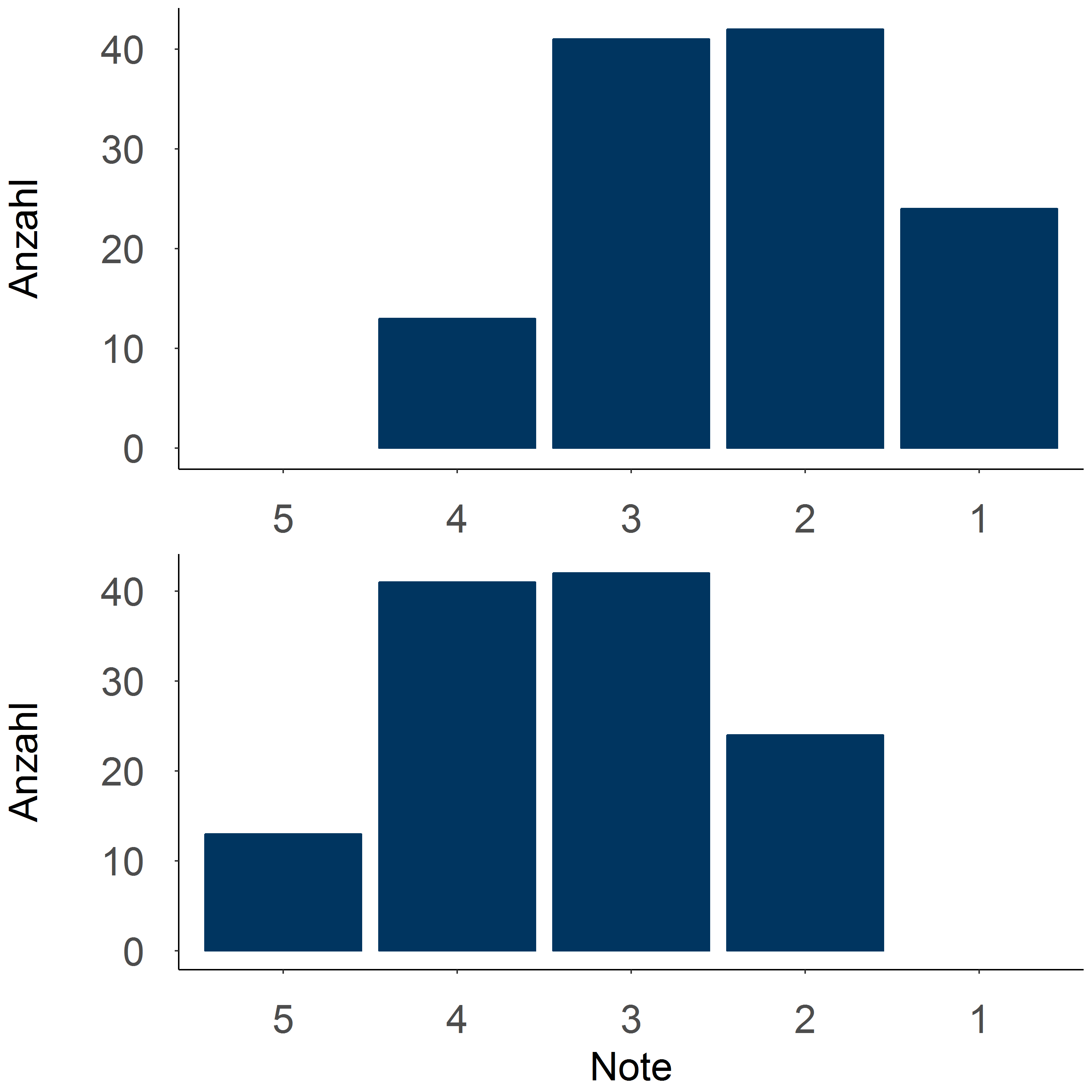
Unterschiedlichkeit der Werte: Haben viele Beobachtungen gleiche/sehr ähnliche Werte oder gibt es hier viel Variation?
Wenn wir wissen, dass "Gut" die häufigste Note war, werden wir als nächstes erfahren wollen, in welchem Ausmaß auch andere Noten vorkamen. Wenn fast alle Schüler*innen ein "Gut" erzielt haben, sprechen wir von einer geringen Variation des Merkmals. Wenn es fast genauso viele ausreichende, befriedigende und sehr gute Noten gab, sprechen wir von einer hohen Variation des Merkmals.
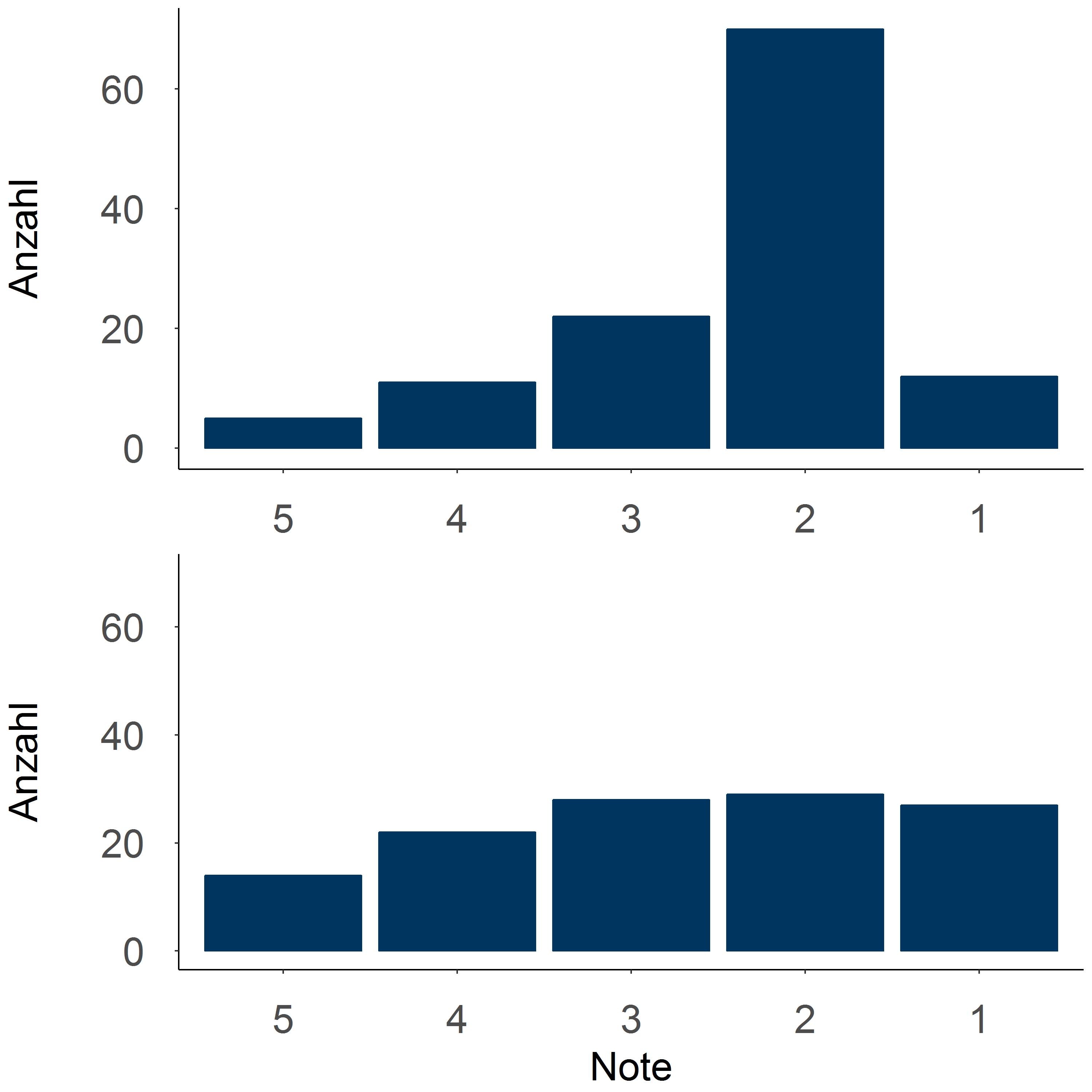
Symmetrie der Verteilung: Wir sprechen von einer symmetrischen Verteilung, wenn die Werte in der oberen Hälfte ähnlich verteilt sind wie in der unteren Hälfte.
Abweichungen von der Symmetrie werden als "Linksschiefe" oder "Rechtsschiefe" bezeichnet (gibt es z.B. mehr Fälle mit Werten im oberen Wertebereich als im unteren, sprechen wir von einer linksschiefen Verteilung).
Wenn wir zusätzlich zur Lage und der Variation der Verteilung der Klausurnoten noch etwas über die Schiefe der Verteilung erfahren, kennen wir die Verteilung schon ziemlich gut. In einer "linksschiefen" Verteilung steigen die Häufigkeiten der Werte im unteren Wertebereich (also "von links kommend") langsam an und fallen im oberen Bereich schnell ab. Ist die Verteilung linksschief, können wir darauf schließen, dass einige "mangelhaft" und "ausreichend" vergeben wurden.
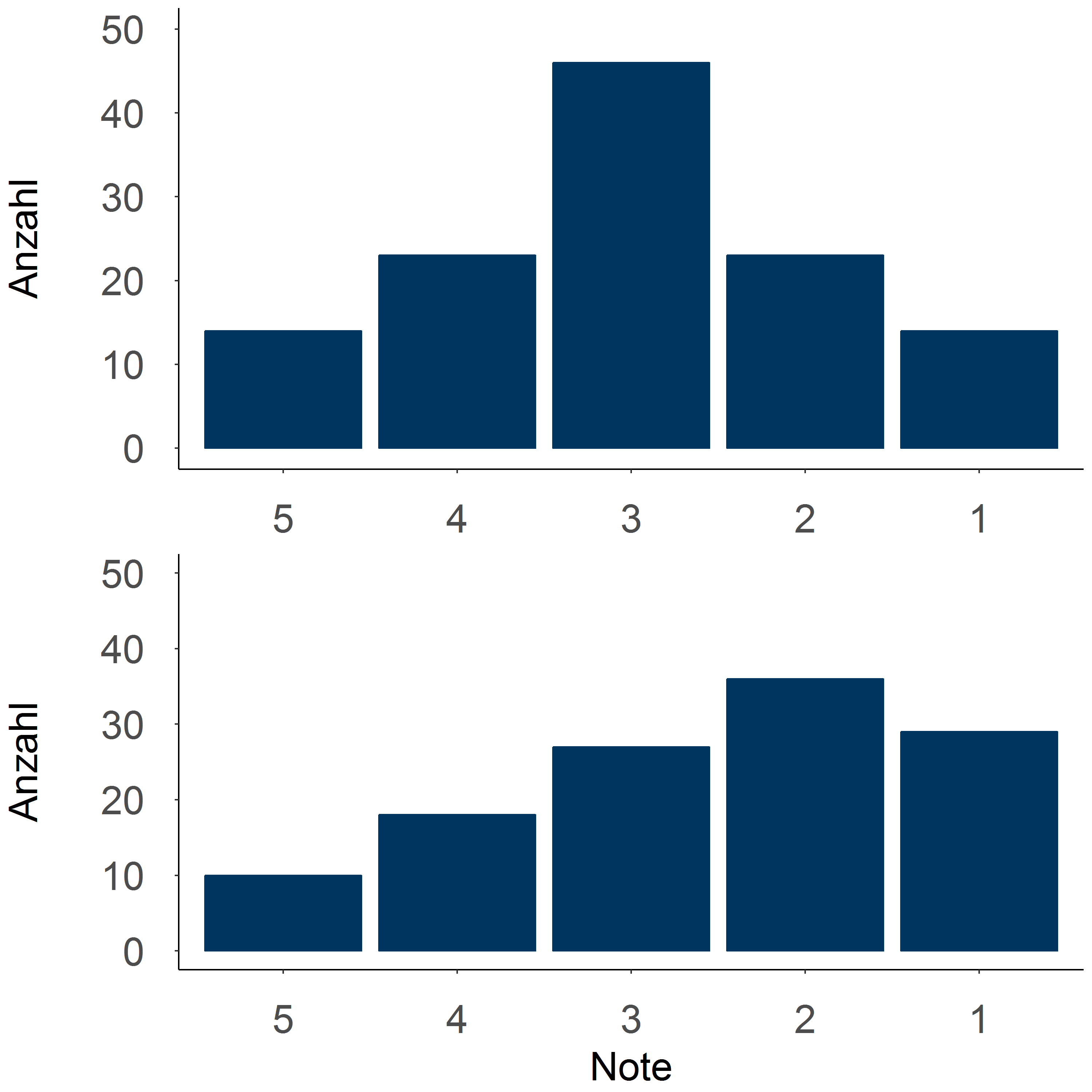
Wahrscheinlichkeitsverteilungen
In diesem Abschnitt wird der Unterschied zwischen (empirischen) Häufigkeitsverteilungen und (mathematischen) Wahrscheinlichkeitsverteilungen erklärt.
Neben der Beschreibung der empirischen Häufigkeitsverteilungen sind wir in Datenanalysen manchmal daran interessiert, ob die empirische Häufigkeitsverteilung eines Merkmals in unseren Daten bestimmten theoretisch-mathematischen Wahrscheinlichkeitsverteilungen entspricht. Wahrscheinlichkeitsverteilungen beschreiben in Form einer mathematischen Funktion, welche Werte mit welcher Wahrscheinlichkeit auftreten.
Wir können eine theoretische Vorstellung davon, wie die Ausprägungen einer Variable bei den Untersuchungseinheiten zu Stande kommen, mit einer solche Wahrscheinlichkeitsverteilung beschreiben. Ein stark vereinfachtes Beispiel im Schulkontext: Wenn wir die "Theorie" haben, dass der Mathelehrer die Noten auswürfelt, würden wir vermuten, dass alle Noten zwischen eins und sechs gleich wahrscheinlich sind — eine Gleichverteilung beschreibt diesen "Datengenerierungsprozess". Wenn wir vermuten, dass alle Schüler*innen eigentlich gleich gut sind und Notenunterschiede nur durch zufällige Unterschiede in "Tagesform" etc. zu Stande kommen, könnte eine Normalverteilung den Datengenerierungsprozess abbilden.
Außerdem setzen statistische Analyseverfahren in der Regel bestimmte Verteilungen der untersuchten Variablen voraus, die daher vor der Anwendung überprüft werden sollten.
Die folgenden Beispiele zeigen Beispiele für häufig verwendete Wahrscheinlichkeitsverteilungen, die unterschiedliche Datentypen und Datengenerierungsprozesse abbilden können.






Häufigkeitsverteilungen darstellen
Wie eingangs dargestellt, gibt es unterschiedliche Möglichkeiten, Häufigkeitsverteilungen darzustellen und zu analysieren. Das genaue Vorgehen wird in den weiterführenden Artikeln beschrieben:
1) Tabellarische Darstellungen bieten sich an, wenn die Verteilung im Detail dargestellt werden soll. Zusätzliche Informationen (z.B. relative oder kumulierte Häufigkeiten) können mitgeliefert werden.
2) Grafische Darstellungen erlauben einen schnellen Überblick über die charakteristischen Merkmale einer Verteilung. Je nach gewählter Darstellungsform können aber auch Details der Verteilung abgelesen werden — gute grafische Darstellungen ermöglichen beides! Einige Darstellungen (wie die oben bereits verwendeten Balkendiagramme) setzen tabellierte Informationen eins zu eins in eine Grafik um, andere bilden zusammmenfassende Berechnungen — statistische Maßzahlen — in grafischer Form ab.
3) Solche statistischen Maßzahlen können auch in Texten oder Tabellen berichtet werden. Mit diesen univariaten Statistiken lassen sich Verteilung knapp zusammenfassen und gut vergleichen. Für die oben unterschiedenen Charakteristika empirischer Häufigkeitsverteilungen existieren jeweils verschiedene statistische Maßzahlen, die Lage, Streuung und Schiefe auf unterschiedliche Art quantifizeren.
In den weiterführenden Artikeln erläutern wir die Lagemaße Modalwert/Modus, Median und arithmetisches Mittel, die Streuungsmaße Spannweite, Quartile, Interquartilabstand, Varianz, Standardabweichung und Variationskoeffizient, sowie den Schiefekoeffizienten.

Dieses Werk ist lizenziert unter einer Creative Commons Namensnennung - Nicht-kommerziell - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz.
Autor*innen dieses Artikels
Sebastian Gerhartz, Lisa Rüge (RUB Methodenzentrum)
Diese Seite wurde zuletzt am 15.01.2024 aktualisiert.